use a subagent to perform a real exam use case check, the subagent read each topic 4-6 one by one, collect all the posible exam point, update the topic exam point md topic by topic, all will under exam question type example context. after finish one exam topic, main thread will use the md along with cheatsheet to do a topic full check, if any not covered, directly fix it. The cheatsheet md will consider the rmd use case in [$rmarkdown-cheatsheet](/Users/lev1s/.agents/skills/rmarkdown-cheatsheet/SKILL.md) , the structure and formula or r output etc. should under a proper format which can easily used by the skill to produce a rmd which can output pdf. Just consider md file in this loop, rmd use will be in next run.
LoserTalk 废物说
废物说聚焦于一个废物想要说的话,不一定是废话,但是费话
-
-
-
- 我现在在做 RankSEG 与 Hugging Face Transformers 的集成设计,目标不是继续维护一个 forked transformers,而是优先在 rankseg 侧实现对 Hugging Face segmentation model outputs 的兼容函数。
背景:
1. 我之前已经在一个本地 transformers 分支里做过一版集成,改的是 `src/transformers/pipelines/image_segmentation.py`,核心思路是在 pipeline 的 semantic segmentation postprocess 阶段加入 RankSEG。
2. 那版实现里最关键的 helper 是:根据不同模型的outputs结构,把它们统一还原成 semantic segmentation 的概率图 `(B, C, H, W)`,然后再交给 `RankSEG.predict(...)`。
3. 现在不想要求用户安装我 fork 的 transformers。更希望最终用户只需要安装官方 transformers 和 rankseg,就能用 rankseg 的 Hugging Face 兼容能力。
已确认的技术判断:
1. 不优先走transformers.pipeline(...)patch 方案,至少第一步不这么做。
2. 不建议给outputs对象动态挂方法,比如outputs.rankseg()`,因为 outputs 类型不统一,很多模型还可能 `trust_remote_code=True返回 tuple 或自定义对象。
3. 更稳的方案是:在 rankseg 里提供 helper
4. RankSEG 真正依赖的不是 pipeline,而是“如何把不同 transformers model outputs 统一成 semantic segmentation probability map”。
请先理解这些 transformers 相关概念:
1.AutoModelForSemanticSegmentation.from_pretrained(...)
是直接加载“任务模型”,不是 pipeline。
2.processor = SegformerImageProcessor.from_pretrained(...)
是加载与模型配套的图像前处理器。
3. 用户一般会这样手动推理:
-inputs = processor(images=image, return_tensors="pt")
-outputs = model(**inputs)
- 然后自己做 resize / argmax / 后处理
4. 我想插入 RankSEG 的位置,就是在outputs之后、argmax 之前。
已探索到的 transformers 输出形态差异:
1. 标准 semantic segmentation 模型:
-outputs.logits
- 对应SemanticSegmenterOutput
- 示例:SegFormer
2. query-based universal segmentation 模型:
-outputs.class_queries_logits
-outputs.masks_queries_logits
- 示例:Mask2Former / OneFormer
3. DETR segmentation 模型:
-outputs.logits
-outputs.pred_masks
4. 还有一些trust_remote_code=True的模型可能不遵循标准ModelOutput`,例如有人直接示例里写 `model(input_images)[-1]
已经看过的本地 transformers 参考位置:
-/Users/lev1s/Documents/GitHub/transformers/src/transformers/pipelines/image_segmentation.py
-/Users/lev1s/Documents/GitHub/transformers/src/transformers/modeling_outputs.py
-/Users/lev1s/Documents/GitHub/transformers/src/transformers/models/segformer/image_processing_segformer.py
-/Users/lev1s/Documents/GitHub/transformers/src/transformers/models/mask2former/image_processing_mask2former.py
-/Users/lev1s/Documents/GitHub/transformers/src/transformers/models/detr/modeling_detr.py
-/Users/lev1s/Documents/GitHub/transformers/src/transformers/models/oneformer/modeling_oneformer.py
rankseg 侧的历史参考:
1. 我之前做过rankseg/paddleseg兼容层,思路是 rankseg 自己提供兼容 facade,而不是修改 PaddleSeg 上游。
2. 这个经验说明:在 rankseg 侧做 Hugging Face outputs 兼容 helper 是合理的。
当前开发目标:
请在rankseg仓库里设计并实现第一版 Hugging Face outputs 兼容函数,优先做最小可用版本,不要过度设计,不要做大而全封装,不要先做 pipeline monkey patch。
建议的第一版 API:
-semantic_probs_from_outputs(outputs, model=None, image_processor=None, target_sizes=None)
-predict_semantic_segmentation(outputs, model=None, image_processor=None, target_sizes=None, rankseg_kwargs=None)
第一版范围只支持:
1.outputs.logits
2.outputs.class_queries_logits + outputs.masks_queries_logits
3.outputs.logits + outputs.pred_masks
设计要求:
1. 保持线性逻辑,避免复杂抽象。
2. 不要先搞通用 CV toolbox。
3. 不要给 outputs 动态挂方法。
4. 不要先做 transformers pipeline patch。
5. 如果某些 output 类型不支持,明确报错即可。
6. 如果需要 resize 到 target size,请参考 transformers 自己 image processor/postprocess 的做法。
7. 如果需要从 query-based outputs 还原 semantic class scores,请参考 transformers 现有 post_process_semantic_segmentation 的实现思路。
如果当前线程有本地两个 repo:
- transformers:/Users/lev1s/Documents/GitHub/transformers
- rankseg:/Users/lev1s/Documents/GitHub/rankseg
请直接在 rankseg 里开发,并可把 transformers 当参考代码读取。
如果ranksegrepo 还没在本地,先确认路径或 clone 后再继续。
工作方式要求:
- 请始终称呼我为 Jasen。
- 默认用中文回复。
- 内部思考和工具使用可用英文。
- 先阅读 rankseg 当前包结构,再决定新增文件位置。
- 优先做最小实现和一个 smoke test/示例,不要额外重构。 -
-
-
- 伊藤润二
- refine_foreground
https://github.com/Photoroom/fast-foreground-estimation - If you need ChatGPT Team:
https://team.aurfox.de/ - 🤪 离谱Linux发行版视频推荐
### 🔥 最离谱的发行版(强烈推荐)
1. 10个真实存在的离谱Linux版本
- [10 Weird Versions of Linux that ACTUALLY Exist](https://www.youtube.com/watch?v=yLy3ygqA5yg) ⭐⭐⭐⭐⭐
- 时长:28分06秒
- 内容:包括Ubuntu Furry Remix、各种奇葩发行版
- 离谱程度:★★★★★
- 适合:纯娱乐,看各种奇葩Linux
2. 离谱到崩溃的Linux发行版
- [Unhinged Linux Distros](https://www.youtube.com/watch?v=EA3PnDXkjlo) ⭐⭐⭐⭐⭐
- 时长:4分26秒
- 内容:真正"unhinged"(精神崩溃)的发行版
- 离谱程度:★★★★★
- 适合:快速了解最离谱的发行版
3. Linux给...毛毛党(Furries)?!
- [Linux for.. Furries? A Look at 3 Weird Linux Distros!](https://www.youtube.com/watch?v=hXslJ_Bxm9U) ⭐⭐⭐⭐⭐
- 时长:36分46秒
- 内容:Linux for Furries、Linux for weebs、Linux for Pentium Pro
- 离谱程度:★★★★★
- 适合:看完你会怀疑这个世界
4. 这是最怪的Linux发行版吗?
- [Is this the weirdest Linux distro? (Nyarch Linux...)](https://www.youtube.com/watch?v=bmz0cmG6gFo) ⭐⭐⭐⭐
- 时长:12分21秒
- 内容:Nyarch Linux(基于Arch+Gnome)
- 离谱程度:★★★★☆
- 适合:深入了解一个最怪发行版
5. 4个你应该避免的最怪发行版
- [Top 4 WEIRDEST Linux Distros You Should AVOID](https://www.youtube.com/watch?v=7wEINCB5ZHQ) ⭐⭐⭐⭐
- 时长:6分10秒
- 内容:怪到根本不该使用的发行版
- 离谱程度:★★★★☆
- 适合:好奇心,但别真去用
### 🐜 极端微型发行版(离谱的小)
6. 21MB的奇迹 - Tiny Core Linux
- [Tiny Core Linux Explained: 21MB Minimal Distro](https://www.youtube.com/watch?v=uoRgfoirVGQ) ⭐⭐⭐⭐⭐
- 时长:4分50秒
- 内容:世界上最小的Linux发行版,只有21MB!
- 离谱程度:★★★★★
- 适合:震惊于如此小的系统能运行
7. Tiny Core Linux基本上是魔法
- [Tiny Core Linux is Basically Magic](https://www.youtube.com/watch?v=sxeRCpg9mfc) ⭐⭐⭐⭐
- 时长:14分23秒
- 内容:深入探索这个21MB的奇迹
- 离谱程度:★★★★☆
- 适合:深度了解微型Linux
8. 制作尽可能小的Linux发行版
- [Making Smallest Possible Linux Distro (x64)](https://www.youtube.com/watch?v=u2Juz5sQyYQ) ⭐⭐⭐⭐
- 时长:27分43秒
- 内容:从零开始制作最小Linux
- 离谱程度:★★★★☆
- 适合:极客思维,了解极限
### 🎮 极端游戏发行版(离谱的强)
9. Garuda Linux - 荒谬到超强的游戏发行版
- [Garuda Linux Distro Is ABSURDLY Over-Powered for Gaming](https://www.youtube.com/watch?v=NDq2qaeHVzg) ⭐⭐⭐⭐⭐
- 时长:12分21秒
- 内容:声称比Windows还强的游戏发行版
- 离谱程度:★★★★★
- 适合:游戏玩家,看看Linux能多强
### 🕵️ 极端隐私发行版(离谱的安全)
10. 政府都害怕的Linux(西班牙语)
- [El Linux que los Gobiernos temen: Qubes, Tails y Whonix](https://www.youtube.com/watch?v=Z17K6WlDHls) ⭐⭐⭐⭐⭐
- 时长:20分30秒
- 内容:Julian Assange、Edward Snowden都在用的Linux
- 离谱程度:★★★★★
- 适合:了解记者、活动家用的系统
11. 隐私OS大对决:Qubes vs Tails vs Whonix
- [Privacy OS Showdown: Qubes vs Tails vs Whonix](https://www.youtube.com/watch?v=9e5huL-yiKw) ⭐⭐⭐⭐
- 时长:8分00秒
- 内容:三大隐私OS终极对决
- 离谱程度:★★★★☆
- 适合:隐私爱好者,了解极致保护
### 🎨 复古发行版(离谱的怀旧)
12. 我让Linux看起来像复古风格
- [I made Linux look RETRO](https://www.youtube.com/watch?v=4w1MPd_Y7EE) ⭐⭐⭐
- 时长:15分24秒
- 内容:基于1985-1999年UI美学
- 离谱程度:★★★☆☆
- 适合:怀旧党,复古美学爱好者 -
-
-
-
- https://pypi.org/project/glassnode-python/
可以,很好,GPLv3开源,这才是真正的互联网精神 -

-
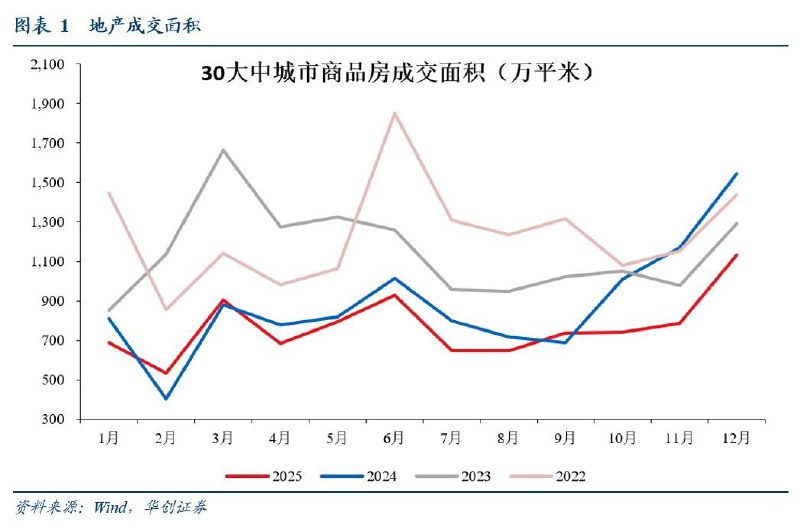
- 修复乏力
-